PDF文档转换为纯文本的目的大多是为了便于编辑、检索和后续处理。本文从最基础的原理讲起,结合通俗的步骤与实际的解决方案,逐步说明如何以最简单的方式完成PDF转TXT转换,并解释常见问题的底层逻辑,便于非专业人员理解并在日常办公中直接应用。
首先说明核心原理。PDF文件本质上是一种页面描述格式,内部可能包含文字对象、矢量图形、位图图片和排版信息。将PDF转换为TXT的关键在于把页面上的“可检索文字”提取出来,并把“不可检索的图像文字”通过识别技术转换成可编辑文本。简单方法的第一步就是判断PDF内部文字是文本层还是图像层:如果是文本层,提取可直接得到准确的字符;如果是图像层,则需要进行图像识别来识别字符。识别过程涉及字符分割、特征提取和字符分类三个基本阶段,现代识别技术通过训练模型将图像像素映射为文字概率,从而输出最终文本。
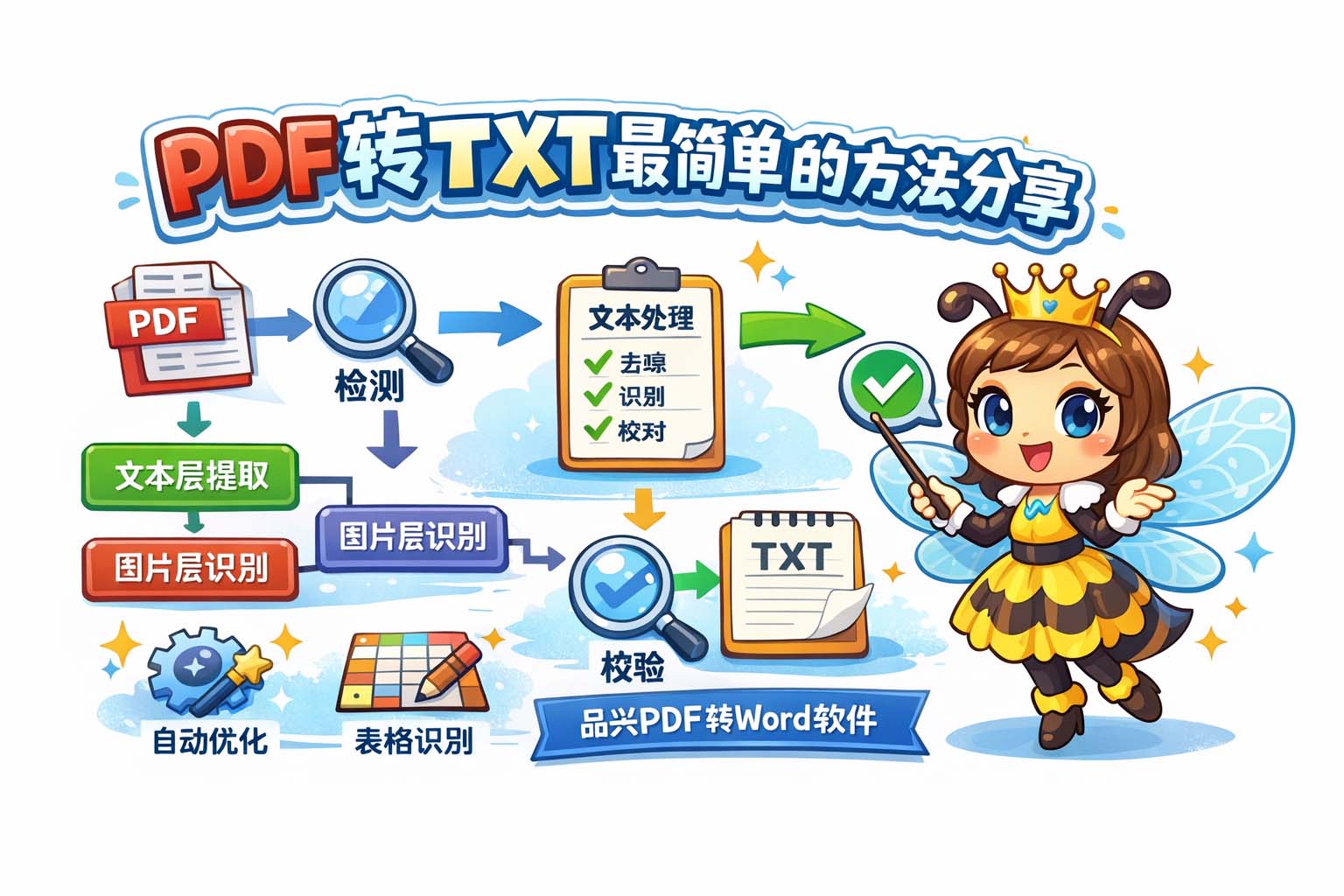
接着给出分步方案,力求清晰可操作。
第一步,确认文件类型与质量:检测PDF是否包含文本层,若有文本层则优先提取;若为扫描件或拍照件则进入识别流程。
第二步,选择合适的识别设置:调整分辨率与灰度化处理可提升识别率,去噪与二值化能减少误判。
第三步,按页或批量处理:对少量页面可逐页转换,批量文件则采用批处理流程,先统一预处理再统一识别。
第四步,对识别结果做后处理:包括合并断行、纠正常见错字、恢复段落结构与去除页眉页脚。
第五步,保存并校验:保存为纯文本后,进行查重与语义检查,确保关键数字、单位与专有名词准确。
针对具体难题提供解决策略。遇到乱码或字符错位时,一般是编码或字体嵌入问题,解决思路是尝试不同编码解析并比对结果;遇到识别率低则检查输入图像分辨率与对比度,适当做锐化和去噪;遇到表格或复杂排版则先按区域分割,针对表格区域采用表格识别的逻辑提取单元格文本,再将单元格内容按行列重建文本结构。对多语言文件,先做语言检测以选用对应识别模型,减少模型混淆带来的错误。
为保证简单性与高效性,推荐按以下要点操作:
一、优先利用文件自身的文本层以获得最高准确率;
二、对扫描件预先做好图像清洗,提升识别输入质量;
三、分段或分区域处理复杂布局,避免整体识别带来的大量排版错乱;
四、设置自动化的后处理规则,如自动合并行、替换常见OCR误识别字符、按特定词典修正专有名词;
五、建立校验机制,针对关键字段做人工抽检或规则校验,保证最终文本可用。
常见的OCR错误包括数字与字母混淆(如把“0”识别为“O”)、连字断开或合并以及标点识别错误。采用词典校正和正则表达式修复可以显著降低错误率,例如用正则把连续数字识别为身份证或电话号码格式进行比对校验,或者用行业词表对专有名词进行候选替换。保存文本时建议统一采用UTF-8编码并注明原文件页码与来源,便于回溯和人工核对。对于需要长期归档的文本,建立版本控制和日志记录,记录转换时间、识别率估算与异常页码,便于二次处理。最后将转换流程模块化,预处理、识别、后处理与校验各自独立,既利于调试也便于在不同场景下替换或优化某一环节,从而实现既简单又可靠的转换流程。
上一篇: 新手常见PDF转TXT失败原因与解决方法
最近更新
相关内容